Applications of Markovian Processes in Economics and Latent Parameters Estimation in Hidden Markov Models
Author: Adrian@Vrabie.net
Adviser: Dr. Habil. Univ Professor Dmitrii Lozovanu
Contens:
- Introduction
- Applications of Discrete State Markov Chains in Economics
- Continuous State Space Markov Chains
- Part II: Estimating the State Transition Matrix
- Code Implementation
Introduction
- Why study Markov Chains?
- What are Markovian Processes?
- What types of questions can we answer using Markov Chains?
Applications of Discrete State Markov Chains in Economics
- First Order Markov Chain
- Stationary Distribution
- Simulating a Markov Chain
- Second and N-order Markov Processes
Continuous State Markov Chains
- Simulating a Continuous State Markov Chain
- Look Ahead Estimate
Part II: Estimating the State Transition Matrix
- The Hidden Markov Model
- Simulating a Hidden Markov Model
- The Forward/Backward Algorithm>
- The Viterbi Algorithm>
- The Baum Welch Algorithm
Why study Markov Chains?
Jeffrey Kuan at Harvard University claimed that Markov models might well be the most “real world” useful mathematical concept after that of a derivative.
Why study Markov Chains?
Markovian processes are used in:
- algorithmic music composition
- google search engine
- asset pricing models
- information processing
- machine learning
- computer malware detection
- speech recognition
- nucleotide sequencing
- lung cancer
- and many more
History of Markov Chains
Andrey Markov wanted to disprove Nekrasov's claim that only independet events could converge on predictable distributions.History of Markov Chains from 4m10s
First Order Markov Chain in Music
What is a Markov Chain?
A Markov Chain is:
a dynamic stochastic process with a Markovian Property
.What is a Markovian Property?
$Pr\left(X_t = x_i |X_{t-1},X_{t-2},...,X_{1} \right) = Pr\left( X_t=x_i|X_{t-1} \right)$First order Markov Chain?
First order Markov Chain?
Applications of Markov Chains in Economics
Applications of Markov Chains in Economics
From Hamilton, Economic Transition
$$\mathbb{A} = \left( \begin{array}{ccc} 0.971 & 0.029 & 0 \\ 0.145 & 0.778 & 0.077 \\ 0 & 0.508 & 0.492 \end{array} \right) $$With the followint payoffs
$$\mathbb{E} = \left( \begin{array}{c} 0.215 \\ 0.015 \\ -0.18 \\ \end{array} \right)$$The Hamilton Matrix simulation
But We will do this later!
Find Eigenvalues and Eigenvectors of $\mathbb{A}$
$$\left| \mathbb{A}-I\lambda \right| = \left| \begin{array}{ccc} 0.971-\lambda & 0.029 & 0 \\ 0.145 & 0.778-\lambda & 0.077 \\ 0 & 0.508 & 0.492-\lambda \end{array} \right| =0$$This gives us:
$$ \mathbf{\lambda} = \left(\begin{array}{c} 1.00000 \\ 0.85157 \\ 0.38943 \\ \end{array} \right) $$Then find the null space for each eigenvalue
We can now calculate the expected payoff conditional on $\mu$
$$\mathbf{S}\mathbf{\Lambda}^{25}\mathbf{S}^{-1} = \left(\begin{array}{ccc} 0.816125 &0.159822 &0.024054 \\ 0.799109 &0.173836 &0.027055 \\ 0.793458 &0.178491 &0.028051 \\ \end{array}\right)$$Simulating Marathon Oil Returns
A little bit of Theory
Irreducible Stochastic Matrices
A stochastic matrix, \(\mathbb{A}\) is irreducible if its graph is strongly connected, that is: there \(\exists \; t \geq 0\) : \(Pr(X_{t}=j|X_{0}=i) > 0 \)
In our example, $\mathbb{A}$ is irreducible since we can end up in any state from any state after \(t \geq 1\) steps.
Aperiodic Stochastic Matrices
A stochastic matrix, \(\mathbb{A}\) is aperiodic if the greatest common divisor of the set S(x) defined as \[S(x) = \{t \geq 1 : P^t(x, x) > 0\}\] equals 1.
We can easily check that matrix \(\mathbb{A}\) from our example is aperiodic.
Stationary Distribution
A probability distribution \(\pi\) over \(X\) is stationary over \(\mathbb{A}\) if: \[\pi = \pi \mathbb{A}\]
Fundamental Theorem of Markov Chains
A theorem proven by Häggström (2002) states that:[Fundamental Theorem of Markov Chains][Haggstrom] If a stochastic matrix \(\mathbb{A}\) is irreducible and aperiodic then there is a unique probability distribution \(\pi\) that is stationary on \(\mathbb{A}\).
provided by Häggström (2002).
Therefore, we can write: $$\lim_{t \to \infty} \mu \mathbb{A}^t = \pi$$
Since all but one of the eigenvalues is smaller than unity.
$$\mathbf{\phi} = \lim_{t \to \infty} \mathbf{S}\Lambda^t\mathbf{S}^{-1} = \mathbf{S} \left(\begin{array}{ccc} 1 &0 &0 \\ 0 &0 &0 \\ 0 &0 &0 \\ \end{array}\right) \mathbf{S}^{-1}$$in our example:
$$\phi = \left(\begin{array}{c} 0.812800, 0.162560, 0.024640\\ \end{array} \right)$$The Hidden Markov Model
The Hidden Markov Model
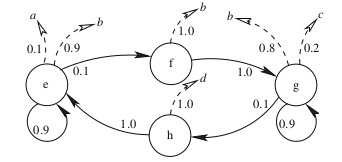
Hidden Markov Model from Fraser (2008, 9)
we have an oriented graph which can easily be transposed to a HMM model.
The Hidden Markov Model
$$\mathbb{A} = \begin{array}{c} e \\ f \\ g \\ h \end{array} \left( \begin{array}{cccc} 0.9 & 0.1& 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0.9& 0.1 \\ 1 & 0 & 0 & 0 \end{array} \right)$$
The emission probabilities for the events \(\Sigma = \{a,b,c,d\}\), as specified in the [smc]: \[\mathbb{B} = \begin{array}{c} e \\ f \\ g \\ h \end{array} \begin{pmatrix} 0.1 & 0.9 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0.8 & 0.2 & 0 \\ 0 & 0& 0& 1 \end{pmatrix}\]
An initial probability distribution among the states $\pi$
The Hidden Markov Model
Formally we define an HMM $\lambda(\mathbb{A,B},\pi)$
Parameters, $\mathbb{A,B},\pi$ are often denoted by $\theta$, thus $\lambda(\theta)$
Simulating a Hidden Markov Model
Using external libraries http://ghmm.org.
$$\mathbb{A}= \left(\begin{array}{cc} 0.9 & 0.1 \\ 0.2 & 0.8 \\ \end{array}\right)$$Emissions: one fair coin and one biased
$$\mathbb{B}= \left(\begin{array}{cc} 0.5 & 0.5 \\ 0.15 & 0.85 \\ \end{array}\right)$$Outcomes: Head (0) or Tail (1).
[1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0 ...
The code is provided in the Annex
Forward, Backward and Viterbi Algorithm
Estimating $\lambda(\mathbb{A,B},\pi)$
Before we estimate $\lambda$, it is helpful to answer the following questions:
- Evaluation: $Pr(\mathcal{O}|\lambda)=?$
- - Use the Forward in combination with Backward algorithm
- Decoding: Most likelihood sequence of states $ \texttt{argmax}_{\mathcal{X}} Pr(\mathcal{O}|\mathcal{X},\lambda)=?$
- - Viterbi algorithm
- Learning: estimate $\lambda$
- - Use the Bayesian rule along with the Markovian property to update the parameters of the HMM: Baum-Welch algorithm.
Probability of $\mathcal(O|\lambda)$
Suppose we have identified a sequence \(\mathcal{O} \in \mathbf{\Omega}\) that we assume is generated by an HMM: \(\lambda(\mathbb{A},\mathbb{B},\pi)\). Given \(\lambda\), we would like to know: \[Pr(\mathcal{O}|\lambda)=?\]
Direct approach
Given a model $\lambda$ a sequence of observations $o_1, o_2, ...$ and states $x_1, x_2, ...$
$$Pr\left(o_1,o_2,...,o_{T} |x_1,x_2,...,x_k,...x_T, \lambda \right)= \pi_i b_i(o_1) \prod_{t=2}^{t=T} a_{t-1,t}b_{a_t}(o_t)$$We then sum over all possible states
$$Pr\left(\mathcal{O} | \lambda \right)= \sum_X \pi_i b_i(o_1) \prod_{t=2}^{t=T} a_{t-1,t}b_{a_t}(o_t) Pr(X|\lambda)$$\[Pr(\mathcal{O}|\lambda)=?\]
The difficulty of this approach is that the total number of possibilities of sequences of states that can generate \(\mathcal{O}\) is exponential in the number of observations \(T\)
$$Pr\left(\mathcal{O} | \lambda \right)= \sum_X \pi_i b_i(o_1) \prod_{t=2}^{t=T} a_{t-1,t}b_{a_t}(o_t) Pr(X|\lambda)$$\[Pr(\mathcal{O}|\lambda)=?\]
A better approach to calculate the unconditional probability \(Pr(\mathcal{O}|\lambda)\) is the forward/backward algorithm which is a class of dynamic programming algorithms and takes advantage of the assumptions of the Markovian processes to filter all possible combinations of states \(X\).
The Forward/Backward decomposition
the objective of the forward/backward algorithm is to compute the probability of being in a particular state \(x_t\) at time \(t\), given a sequence of observations \(\mathcal{O}\)
$$Pr(x_k | \mathcal{O})= ? , k \in \{1..T \}$$The Forward/Backward decomposition
$$Pr(x_k | \mathcal{O}, \mathbf{\lambda}) = \frac{Pr(x_k, \mathcal{O} | \mathbf{\lambda})}{Pr(\mathcal{O}|\mathbf{\lambda})} = $$
$$\frac{Pr(x_k,o_1,o_2,...o_k |\mathbf{\lambda} )*Pr(o_{k+1},...,o_T|x_k,o_1,...o_k,\mathbf{\lambda})}{Pr(\mathcal{O}|\mathbf{\lambda})}$$
using the Markovian property:
$$Pr(x_k | \mathcal{O}, \mathbf{\lambda}) = \frac{Pr(x_k,o_1,o_2,...o_k |\mathbf{\lambda} ) Pr(o_{k+1},...,o_T|x_k,\mathbf{\lambda})}{Pr(\mathcal{O}|\mathbf{\lambda})}$$
The Forward/Backward decomposition
We denote: $$\alpha_i(k)=\alpha\left( x_k=i \right) = Pr(o_1,o_2,...o_k,x_k | \lambda) \quad\quad o_k \in \mathcal{O}, k=\overline{1,T}$$ $$\beta_i(k)=\beta(x_k=i) = Pr(o_{k+1},o_{k+2},...,o_{T} | x_k=i, \lambda) \quad i=\overline{1,N}, k=\overline{1,T}$$$$Pr(x_k=i | \mathcal{O}, \mathbf{\lambda}) = \frac{\alpha_i(k) \beta_i(k)}{Pr(\mathcal{O}|\mathbf{\lambda})} =$$
$$ \frac{\alpha_i(k) \beta_i(k)}{\sum_{i=1}^N \alpha_i(k=T)} $$
The Forward algorithm
\begin{aligned} \alpha_i\left( x_k \right) =& \sum_{x_{k-1}} Pr(o_1,o_2,...o_k,x_{k-1},x_k | \lambda) \\ = &\sum_{x_{k-1}} Pr(o_k | o_1,o_2,...o_{k-1},x_{k-1},x_k, \lambda)\times \\&Pr(x_k|o_1,o_2,...o_{k-1},x_{k-1},\lambda) Pr(o_1,o_2,...o_{k-1},x_{k-1}|\lambda) \\ =& \sum_{x_{k-1}} Pr(o_k | x_k, \lambda)Pr(x_k|x_{k-1},\lambda) \alpha\left( x_{k-1} \right) \\ =& \sum_{x_{k-1}} \mathbf{b}_{x_k}(o_k) \mathbf{a}_{(k-1,k)}\alpha\left( x_{k-1} \right) \\ =& \mathbf{b}_{x_k}(o_k) \sum_{x_{k-1}} \mathbf{a}_{(k-1,k)}\alpha\left( x_{k-1} \right) , \quad x_{k-1}=\overline{1,N}, k=\overline{2,T}\end{aligned}The Backward algorithm
Similarly: $$\begin{aligned} \beta(x_k) &= \sum_{x_{k+1}}\beta(x_{k+1})\mathbf{b}_{k+1}(o_{k+1})\mathbf{a}_{k,k+1}, \quad\quad k=\overline{1,T-1}\end{aligned}$$Decoding: The Viterbi Algorithm
Given $\lambda$, our objective is: $$Pr\left(\mathcal{O}, x_1,x_2,...x_T,| \lambda \right)= \underset{X}{\operatorname{argmax}} \: \pi_i b_i(o_1) \prod_{t=2}^{t=T} a_{t-1,t}b_{a_t}(o_t)$$ $$Pr(x_1=k|o_1,\lambda) = \frac{Pr(x_1=k,o_1)}{\sum_{x_1\in S}Pr(x_1,o_1)}= \frac{\pi_{x_1}b_{x_1}(o_1)}{\sum_{x_i \in S} \pi_{x_i}b_{x_i}(o_1)}$$ $$V_{1,k}=\pi_{x_k}b_{x_k}(o_1)$$ $$V_{t,k} = \underset{x_{t-1}\in S}{\operatorname{max}}\left( V_{t-1,x_{t-1}} \mathbf{a}_{x_{t-1},k} \mathbf{b}_{k}(o_t) \right)$$Baum Welch algorithm: estimating $\lambda$
Given an observable sequence \(\mathcal{O} = \{o_1,o_2,...,o_T \}\) and assuming this sequence was generated by an HMM model \(\lambda(\mathbb{A,B},\pi)\) we want to find out the most likely set of parameters of \(\lambda\) that generated the sequence \(\mathcal{O}\). we want to find out \(\theta\) that maximizes the probability:
$$\theta^{\star} = \underset{\theta}{\operatorname{arg\, max}}Pr\left(\mathcal{O} | \lambda(\theta)\right)$$Substituting: $$\bar{a_{ij}} = \dfrac{ \dfrac{\alpha_i(t) a_{ij} b_j(o_{t+1}) \beta_j(t+1)} {\sum_{i\in S}\sum_{j\in S} \alpha_i(t) a_{ij} b_j(o_{t+1}) \beta_j(t+1) }} {\dfrac{\alpha_i(t) \beta_i(t)}{\sum_{j \in S}\alpha_j(t) \beta_j(t) }} $$
example on nucleotides, assuming 2 states:
There is much more:
This presentation: moldovean.github.io
replicate results : github.com/moldovean/usm/tree/master/Thesis